


2021年8月24日(火)から26日(木)までの3日間、日本最大のコンピュータエンターテインメント開発者向けカンファレンス「CEDEC2021」(CEDEC=セデック:Computer Entertainment Developers Conference 主催:一般社団法人コンピュータエンターテインメント協会、略称CESA)が開催。昨年に引き続き、新型コロナウィルス感染拡大を防止する観点から本年もオンラインで開催された。
本稿では、8月24日(火)に開催されたセッション「スマホ音楽ゲームが変わる!楽器レベルの低遅延再生への挑戦」の模様をレポートしていく。
【講演者】

株式会社 CRI・ミドルウェア 代表取締役社長。早稲田大学理工学部機械工学科卒業後、人工知能研究者としてCSK総合研究所(CRI)に入社し、セガサターン・ドリームキャストの映像・音声関連のシステムソフト開発に従事。その後、CRI・ミドルウェアの創業メンバーとして参画、2013年に同社代表取締役に就任する。

株式会社CRI・ミドルウェア エンターテインメント事業本部 研究開発部エンジニア。サレジオ工業高等専門学校 情報工学科 本科 卒業後、株式会社CRI・ミドルウェアに入社。「CRI ADX2」のライブラリ開発を担当している。

株式会社 CRI・ミドルウェア エンターテインメント事業本部 研究開発部リードエンジニア。2000年にCRI・ミドルウェアに入社し、主に「CRI ADX2」の設計開発を担当。「ADX2」に搭載されている高圧縮の独自コーデック「HCA」を開発する。
音声遅延とユーザー体験
本講演では、株式会社CRI・ミドルウェアが挑戦し続ける、業務機や家庭用ゲーム機と同程度の低遅延再生を、スマホ音楽ゲームで実現する手法についての解説が行われた。
まず同社が提供する低遅延再生技術「SonicSYNC」について。本技術は、タイトーがリリースしたスマートフォン向けリズムゲーム『ディズニー ミュージックパレード』で採用されている。
ゲームの特徴は、タップ音が楽曲に合わせて音階が変わり、まるで演奏しているような感覚を味わえるという点であるが、これに低遅延再生技術を取り入れることで、その感覚がよりリアリティを増していく。
また、家庭用やアーゲードのリズムゲームと同じような高いレスポンスを実現しているほか、Bluetoothイヤホンの遅延があったとしても気持ちのいいプレイができるといった、高い評価を得ている技術だ。

このような技術を実現するためには、「同時性」と「周期性」を理解する必要がある。まず音声の「同時性」とは、映像と音声が同期(リップシンク)していて、セリフや効果音のタイミングが一致していること。また、楽器演奏の様に複数の音声が同時に発音する、複数の音声の同期のこと。このふたつが、同時性のテーマであると語られた。

映像と音声のズレを知覚する時間というのは、音声が速い場合は45ミリ秒、逆に遅い場合は90ミリ秒というように、遅い場合の方が知覚されにくいという特徴がある。これは、光の方が音よりも早いため、音が遅くなる場合よりも早い方が違和感を感じやすいという。
雷のように、光が届いてから音が来るというものが実は日常的にあるため、音が届くのが早い場合のほうが、違和感が生まれやすいのだそうだ。

また、ふたつの音を右側と左側で徐々にタイミングをずらして再生した場合、10ミリ秒ほどすれた時点で、異なるふたつの音として知覚できるという。

次に、楽器の反応速度について。グランドピアノのような鍵盤を叩いて音を出す楽器は、打鍵から音が出るまでに多少のズレがある。このように、楽器を演奏する際は、どうやってもディレイ(遅延)が発生してしまう。
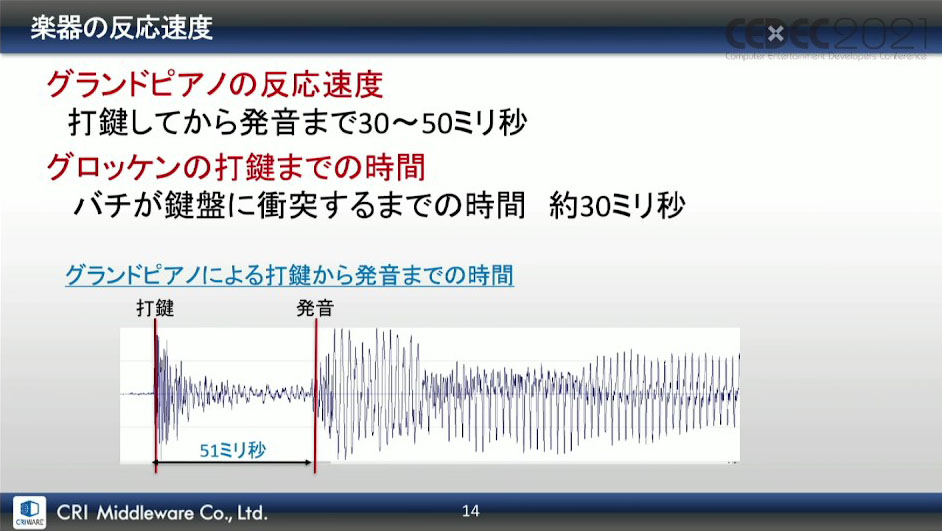
プロの演奏家などがこのディレイを予測してタイミングを調整しているように、人間には遅延を予測してタイミングを合わせて筋肉を動かす力があるのだが、遅延時間が長いと音楽の楽譜と混乱が発生してしまうそうだ。
遅延時間が50ミリ秒以内であれば人間がコントロールできる範囲内に入るため、低遅延再生技術を実現させるにあたって、この50ミリ秒以内という数値を目標に開発していったという。

続いて、音声の「周期性」について。これは等間隔でビートを刻んだ時の周期のことを言う。120テンポという数値を基準とした場合、この違いが認識できるようになる範囲が、122(拍間との差が8ミリ秒)ほどとのこと。ちなみに、絶対音感のように聞いただけでテンポの周期がわかる絶対テンポという人がいるそうだ。

また、周期性の方が同時性よりも繊細に知覚でき、2~4ミリ秒ずれると、揺らぎとして聞こえてしまうという。

正確な周期性を実装するのは大きなテーマであり、ズレを先ほどの2~4ミリ秒に抑えようとすると非常に難しい。そこで、ポジショニングといった計算負荷の高い3D関連は、映像に合わせて16.7ミリ秒で計算する。そこに、ビートと同期させるためにプリディレイ(無音)を挿入して調整すれば、CPU負荷を抑えながら正確性を上げることが可能になると説明した。

低遅延再生のための基礎
ここからは、低遅延再生を実現するための基礎が解説された。
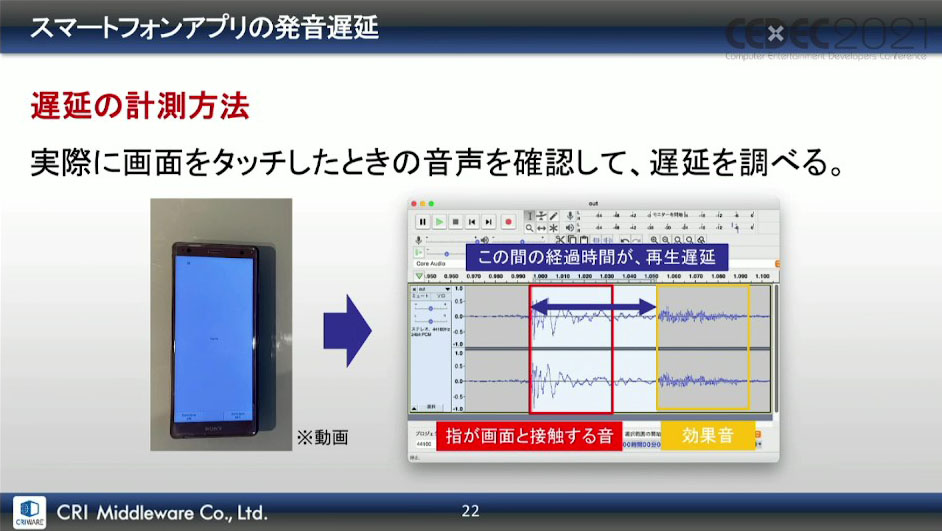
まず、重要になる発音遅延の説明。発音遅延とは、たとえばスマートフォンの画面タップ、コントローラーのボタン入力といったように、発生のトリガーとなるユーザーの操作を受けた後に、SEなどの指定された音声が出力されるまでの時間のことを指す。
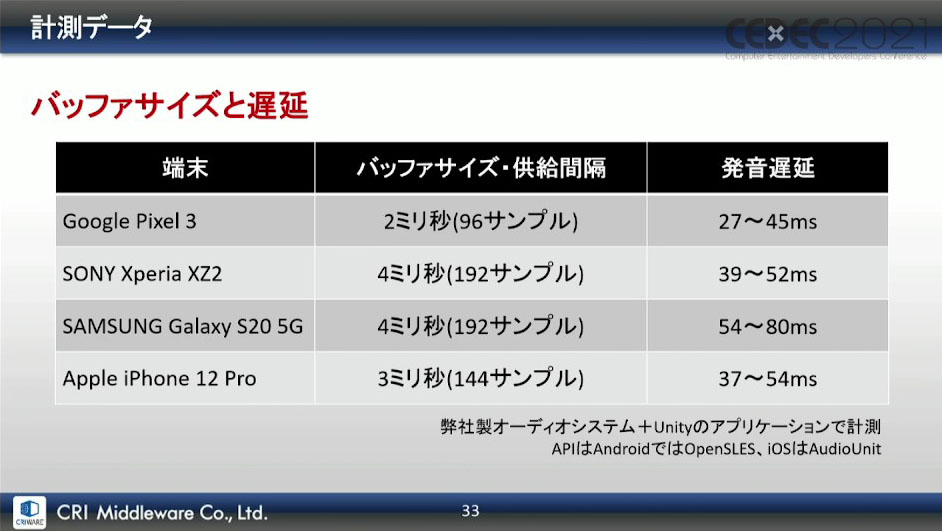
この発音遅延を計測するために行われた方法として、画面をタップするとSEが出力されるようにしておき、その音声を確認・計測したという。実際のスマートフォンでゲームを作る場合は、条件はこの計測時と同じになるそうだ。
サウンドがデバイスから出力されるまでの流れとしては、アプリケーションから再生命令を受け、オーディオシステムが音声データをOSに供給するという形になる。

オーディオシステムから音声を出力する仕組みは、クロスプラットフォーム向けの場合、メインのシステムは共通のコードで実装されるが、音声出力に関しては、各プラットフォーム向けに提供されているAPIを使用するとのこと。

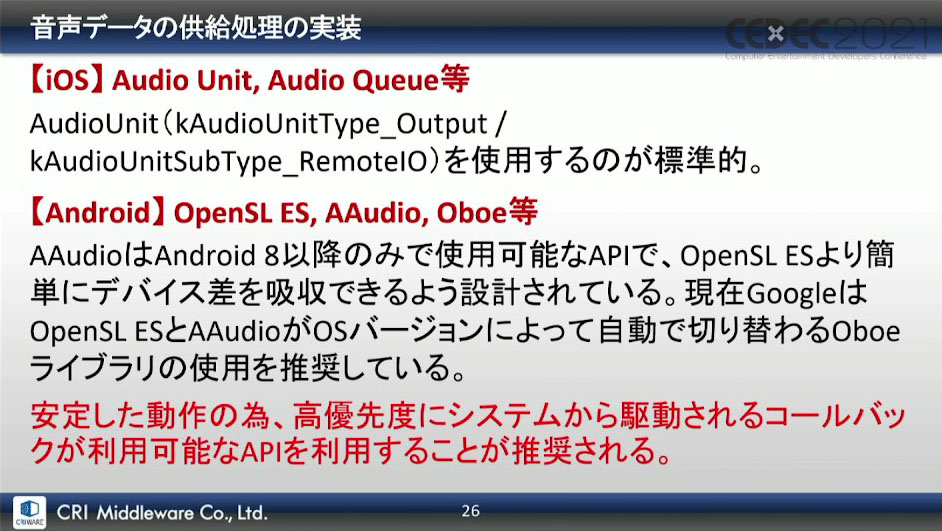
ここで、実際に起きてしまう遅延について、いくつかに分類してその原因が紹介された。まずは、ソフトウェア起因の遅延について。主に考えられるのは、「アプリケーションとオーディオシステム間(再生命令間)の遅延」、「オーディオシステム内での遅延」、「オーディオシステムとOSとの間の遅延」などがある。

「オーディオシステムとOS」のデータのやり取りでは、生成した音声データをPCM形式でOSに定期的に供給するのが一般的のため、音声データは実時間に伴って供給量が決定する。

この定期的な処理によって何が発生するのか。それは、OSに音声データを送る機会が5ミリ秒ごとの場合、新しい再生データを供給するためには、最大で5ミリ秒の遅延が発生する可能性があるということ。
そのため、音声データの供給感覚が小さいほうが、新たな音声データをOSに供給するまでにかかる時間を短縮できるという。

例として、実際にスマートフォンに実装する際の方法が紹介された。まずiOSでは、OS側がハードウェアとデータをやり取りするサウンドバッファの大きさを変更できる。バッファの大きさの変更に伴って、データをやり取りする頻度も変化する仕組みになっており、この具体的なバッファの大きさや変更は、特定の関数(下画像参照)によって変更ができるという。

Androidでは、ハードウェアごとに音声データをやり取りするバッファサイズが固定されているため、変更ができないそうだ。しかし端末ごとの定数値は下画像の関数で取得ができ、サウンドデータを供給する際、この値に合わせてデータを定期的に供給することで、そのハードウェアにおける最小の遅延で音声が出力できるとのこと。

ここからは、実際にスマートフォンOSに低遅延再生を実装する問に注意すべき点が紹介された。
まずは、iOSとAndroidどちらにもある点として、OSによってデータ供給間隔が強制的に変更される場合があるそうで、原因となる現象を回避しなければ、安定した低遅延再生にはつながらない。なお、データ共有間隔の変更は完全に無効化することはできないため、オーディオシステム側をデータ供給間隔の動的な変更に対応できるようにしておく必要があるそうだ。
また、Androidは様々なデバイスで実行されることを想定してデザインされているため、ハードウェアの特性に合わせて音声データを変換する内部処置があるため、遅延減少のためにはこの処理を回避しなければならないとのこと。
さらにAndroidでは、一部のBluetoothデバイスの再生時のみ、データ供給間隔が変化してしまうことがある。他にも、供給しているデータとハードウェアのサンプルレートが異なると、OS内部でリサンプリングの進行処理用のルーティングが行われて、遅延が増加してしまう。これに対しては、同じサンプルレートでデータを供給する必要があるそうだ。
またiOSでは、バックグラウンド再生やPicture-in-Picture再生によって、別アプリから音声を同時に再生すると、データ供給間隔の変更が発生してしまう。有効な対処法としては、アプリケーション起動時にバックグラウンド再生を停止する挙動を組み込むなど、バックグラウンド再生を許容しない設定にすることだという。
ここまでのまとめとして、OSとサウンドシステム間での遅延を減少させるには、①オーディオ供給処理をなるべく小さい間隔で行う、②OS内での意図しない信号処理をなるべく発生させないようにする、③システムが提供するAPIの仕様を把握して音声データの供給間隔をハンドリングする。この3つを抑えてほしいと説明した。
低遅延再生実装のためのソフトウェアアーキテクチャ
続いて、圧縮音声のデコードやピッチ変更やミキシングといったものを含めて、一般的なソフトウェアシンセサイザーでの低遅延再生を検討した際、どのようにするのかが解説された。

必要な要素技術としては、オーディオシステムはOSのデータ要求タイミングに合わせて音声データを書き込むのが望ましいという。この機能を実現するため「オーディオコールバック」というものを使用するそうだ。

オーディオコールバックとは、OSが音声データの書き込みタイミングを通知するための仕組みのこと。あらかじめ登録しておいたコールバック関数が、音声データの書き込みに最適なタイミングで定期的に呼び出される。これは、iOS、Androidのどちらでも利用可能な仕組みとなっている。
これを利用すると、音声データが必要になったタイミングでコールバック関数が呼び出されるため、ユーザースレッドによるポーリングよりも遅延が少ない。さらに、ユーザースレッドよりも高い優先度で実行されるため、たとえアプリケーションが後負荷でも、コールバック関数は途切れずに実行できるというメリットがある。
このように有利性が多いため、すべての処理をオーディオコールバック内で動作させるのが理想形だったが、この方式は採用できなかったという。
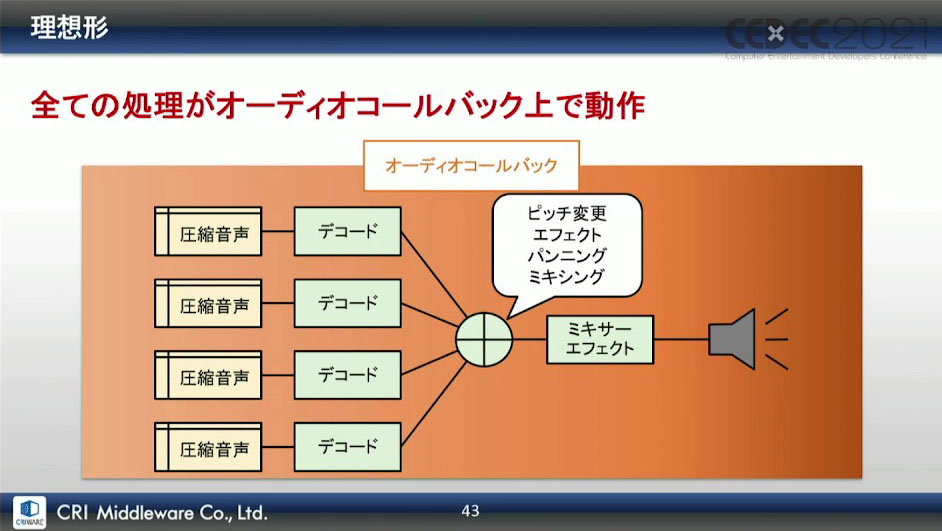
オーディオコールバック内で処理をする場合、音を途切れさせないためには、オーディオコールバック内の処理を、オーディオフレーム時間内に終わらせる必要がある。サウンドバッファサイズを小さくすれば音声遅延は小さくなるが、単位オーディオフレームあたりに許容される処理時間も合わせて短くなってしまう。
また、圧縮音声データのデコードやエフェクト処理には、固有の「処理速度」があり、任意のサンプル数で音声データを処理するのが難しくなってしまう。
粒度の大きな処理があると、オーディオフレームごとの処理量にばらつきが生じる。つまり、処理粒度による負荷が変動してしまうという。

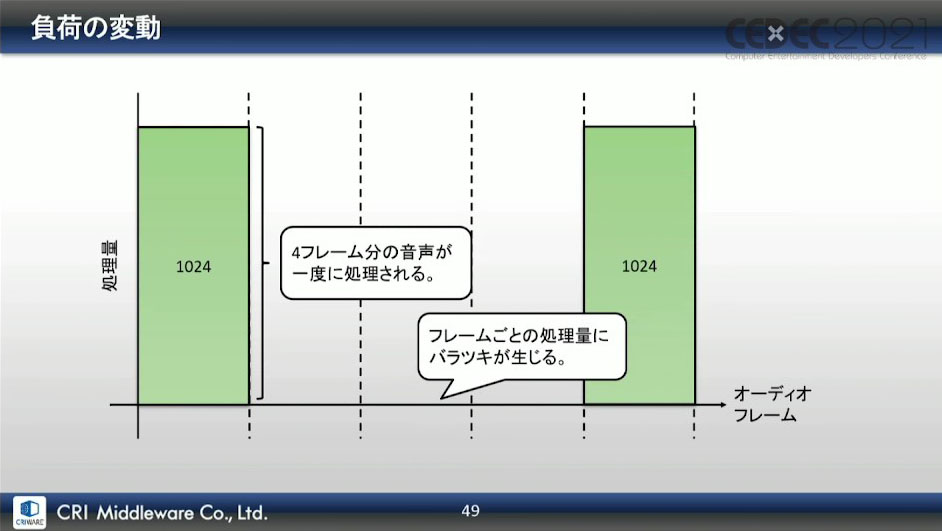
このような処理粒度の違いによる負荷変動といった理由から、すべての処理をオーディオコールバック内で動作させる理想は実現せず、この方式は採用できなかったという。
そのため、その負荷変動への対策を検討したそうだ。理想的には処理粒度自体を小さくすることだったが、信号処理アルゴリズム上の制限で実現できなかった。そこで、他のスレッドに処理を分散させて、オーディオコールバック内の処理量を減らすことで、負荷分散を行ったそうだ。しかし、この方式も実現しなかったという。
理由としては、オーディオコールバックと別のスレッドを連結して動作させる場合、スレッドの動作周期がネックになるほか、オーディオコールバックには時間的な制限があるため、他スレッドを待つことを回避しなければならない、排他制御の問題が浮上してしまったからだそうだ。
この問題の解決として、オーディオコールバックの消費量を考慮した中間バッファを用意してスレッドからデータを供給することで、動作周期の差を吸収でき、排他制御区間が中間バッファへのデータ読み書きタイミングに限定されるため、広範囲の排他制御をおこなう必要がなく、オーディオコールバック内での長時間ロックを回避できた。
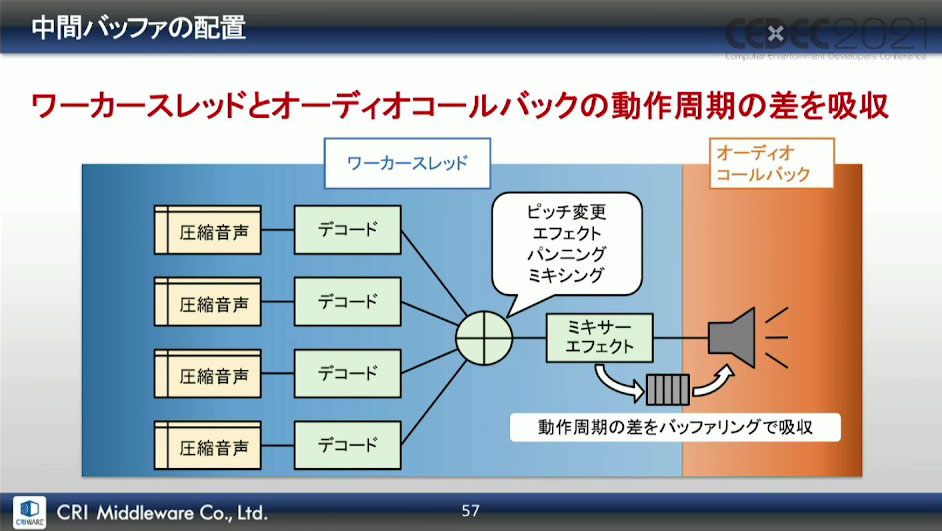
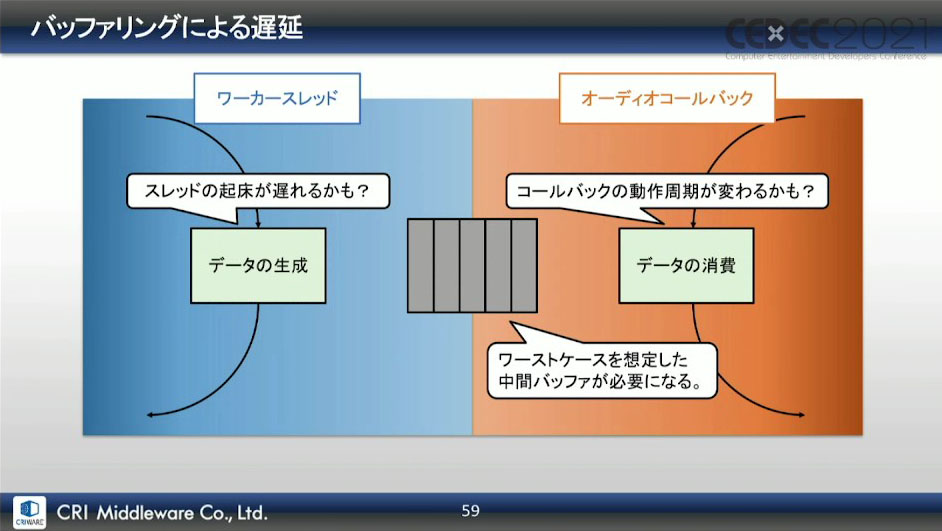
しかし、またしても問題が発生。最悪の動作周期を回避できる中間バッファを用意しなければいけないのだが、バッファサイズに比例して発音遅延も大きくなってしまうことが露呈してしまった。バッファサイズが小さければ問題ないが、最終出力段のワースト処理粒度やスレッドの動作遅延があるため、サイズがどうしても大きくなってしまったという。
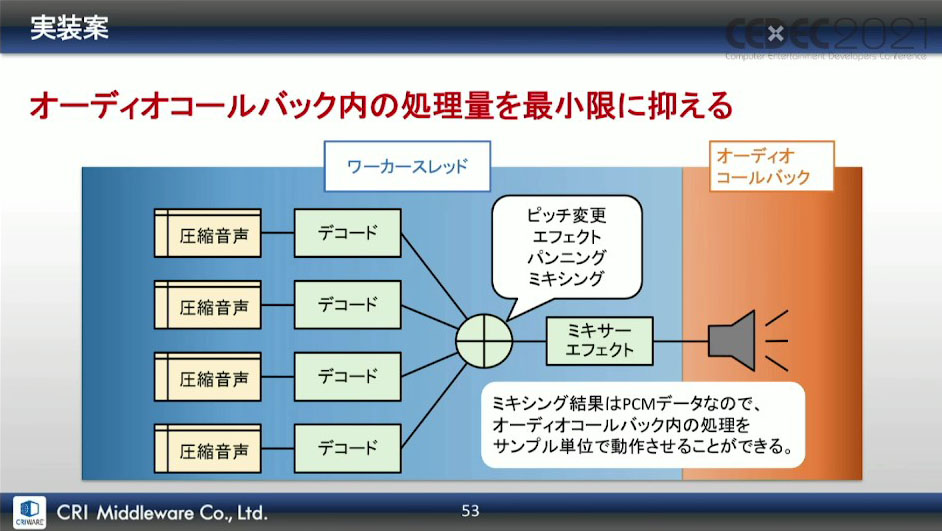
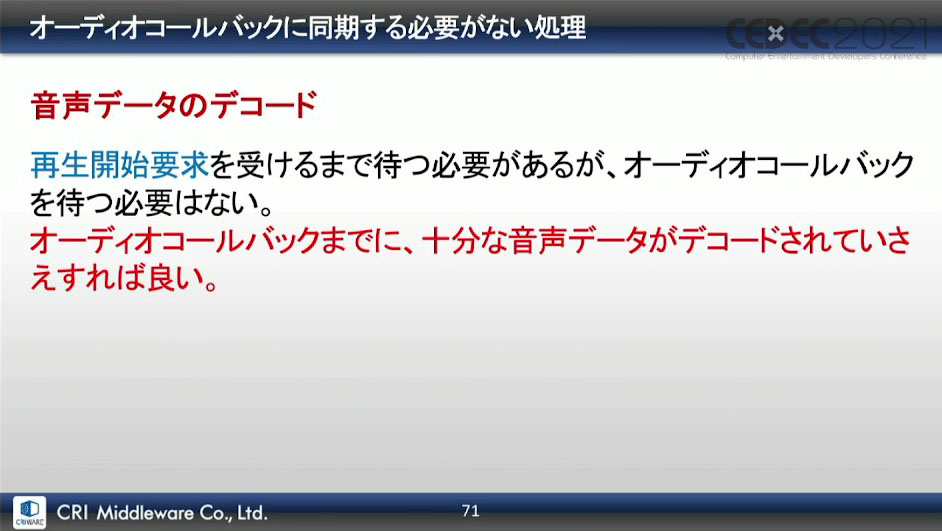
そこで、並列処理方法の見直しを行ったそうだ。遅延の原因となる処理はオーディオコールバックで動作させ、オーディオコールバックに同期する必要がないもののみ、別スレッドで動作させるということになったという。



こうしてできた改善案の図が下画像になる。ピッチ変更・エフェクト・パンニング・ミキシング・ミキサーエフェクトはオーディオコールバック内で動かし、図の位置に中間バッファを配置する形になった。
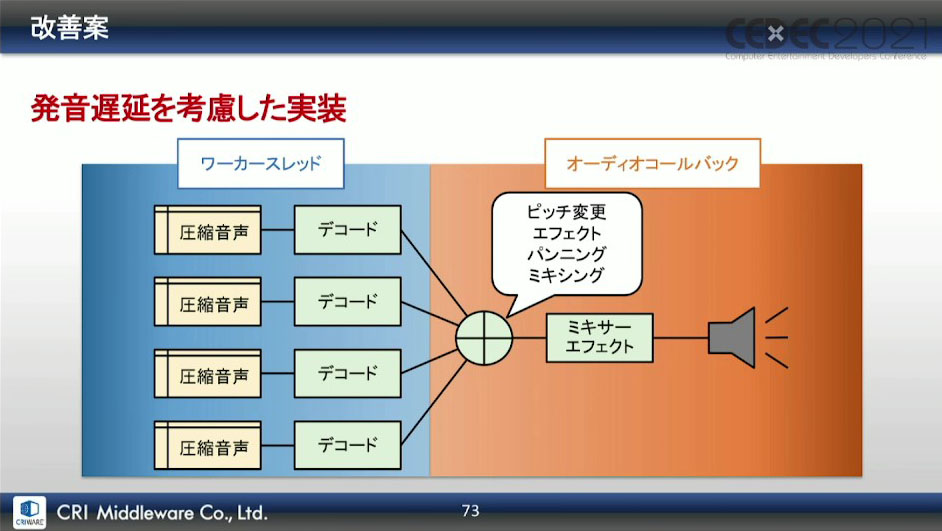
サウンドバッファに限らず、バッファリングを行うことは遅延に繋がるというわけではなく、発音要求からミキシングまでの時間が変わらなければ、途中経過でバッファリングを行うこと自体は問題ないそうだ。
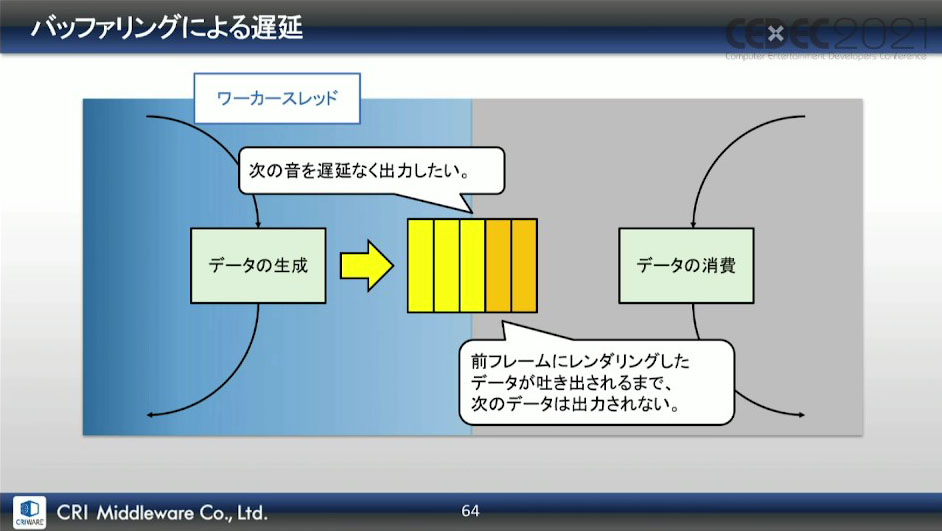
最終出力段でのバッファリングでは、アプリケーション使用中は常にバッファリングが行われているため、バッファ内に残っているデータが吐き出されるまでは、次のレンダリング結果が出力されない。
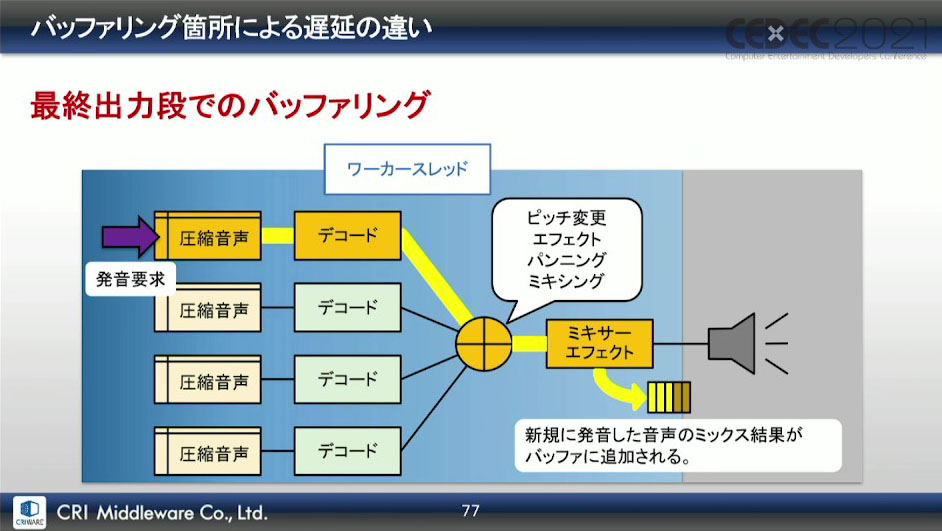
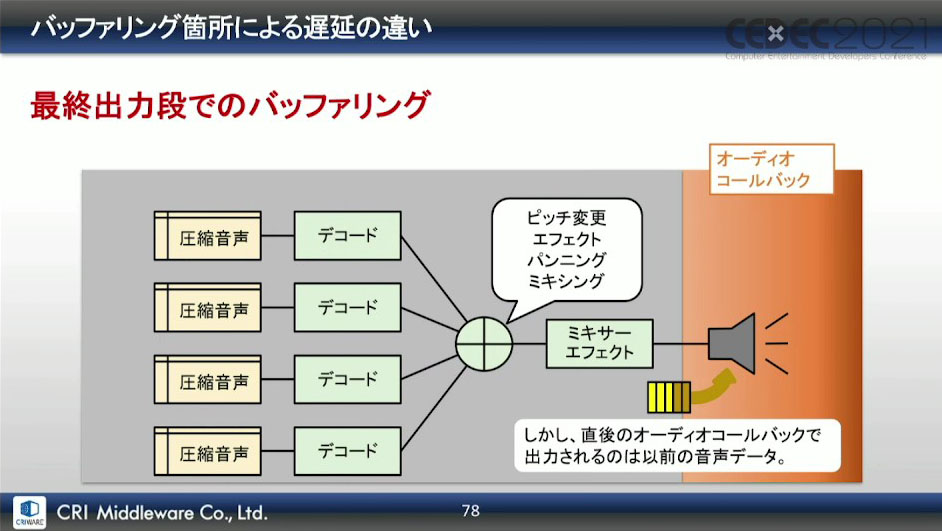
しかし、発音ごと(ボイス単位)でバッファリングであれば、発音開始までバッファは空の状態であり、バッファに書き込まれたデータが、直後のオーディオコールバックで遅延なく出力される。
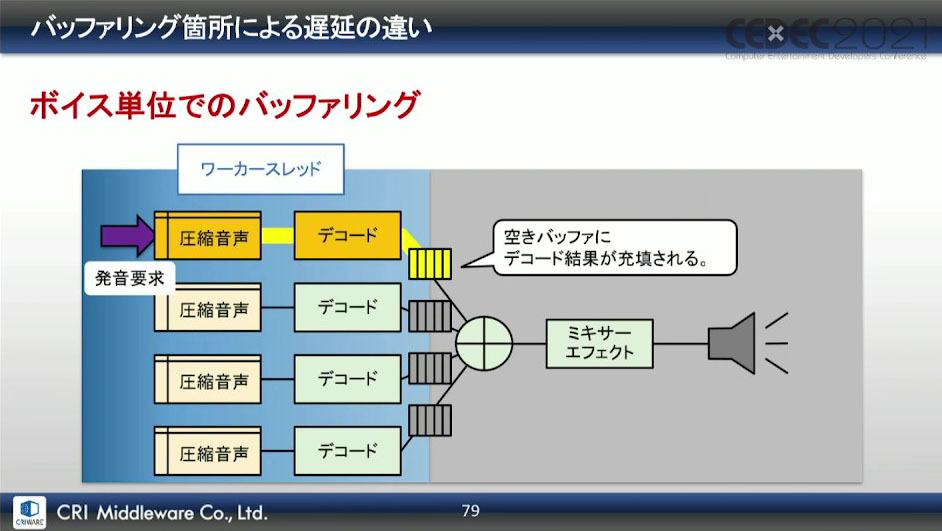
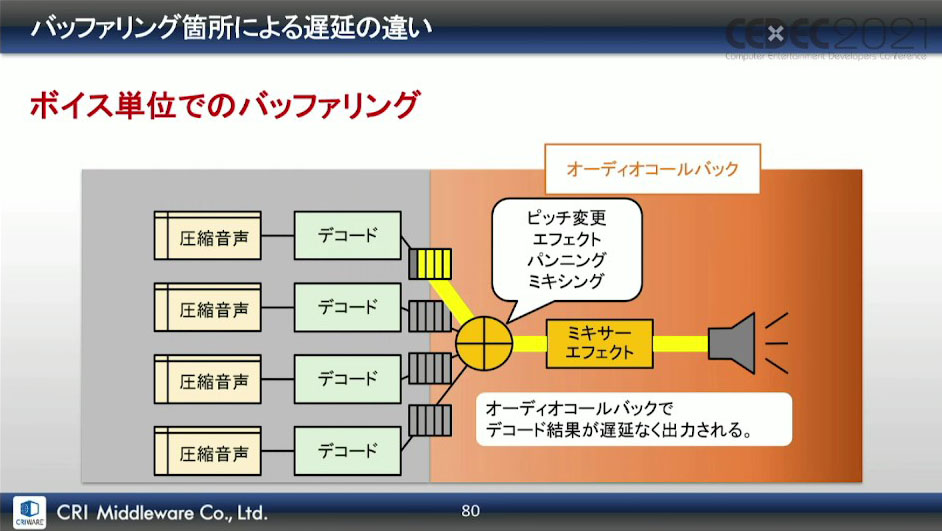
この効果としては、最終出力段の直前でのバッファリングが無くなり、発音遅延を解消。デコード処理を他スレッドに分離したことで、オーディオコールバックの処理負荷も、実用上問題なレベルに落ち着かせることができたそうだ。
ただし、ボイス単位でワーストの処理粒度に合わせた音声データをバッファリングするため、メモリの使用量が増えるのが難点だが、ここが致命的になることはないという。
続いて処理粒度変化への対応だが、音を途切れさせないために、最終出力段の処理速度が変化した際に、粒度変化に応じて音声データのデコード量を増やす必要がある。そのため、短時間に大量の音声データをデコードする場合に、局所的に大きな負荷が発生してしまう。
そのためのデコード負荷対策としては、中間バッファ自体は最終出力段のワースト粒度に合わせて用意し、デコード速度を再生レートの2倍程度に抑え、負荷変動が顕著にならないレベルで少しずつデータを貯蓄する方法を試したという。これによって、再生中に最終出力段の粒度が変更された場合でも、貯蓄分である程度のカバーができるという作戦だ。


効果としては、発音開始時に常に大きな負荷がかかる問題を回避し、最終出力段の粒度が変わった場合でも音が途切れるのをある程度回避できるようになった。
しかし、再生開始直後のデータが不十分なタイミングで粒度が変化すると、音が途切れてしまう可能性はあるという。ただ、あくまでピーク負荷を抑えつつ耐障害性を高める手段としては有効ではないかという結論に至ったそうだ。
総括として、今回紹介された技術によって、グランドピアノと同等のレスポンスを実現し、実ゲームで楽器演奏の爽快感を生み出したこと、スマートフォンはあくまで電話であり、様々な状況の変化があるため、それに動的に対応してきたこと、「トヨタの看板方式」のような信号生成方式と発音要求のタイミングで「材料の仕入(デコード)」を行うことを組み合わせ、コールバックに同期した低遅延信号処理を実装したことをまとめ、締めとした。
